This project was a deep collaborative effort between myself (Manan Dua) and my partner, Mohammad Mustafa. Unlike typical projects where components are split entirely, we worked together on the conceptualization, state machine design, and board testing for every single milestone. We utilized pair programming for the critical debugging phases to solve complex timing violations.
To maximize efficiency, we divided the specific implementation tasks within each milestone:
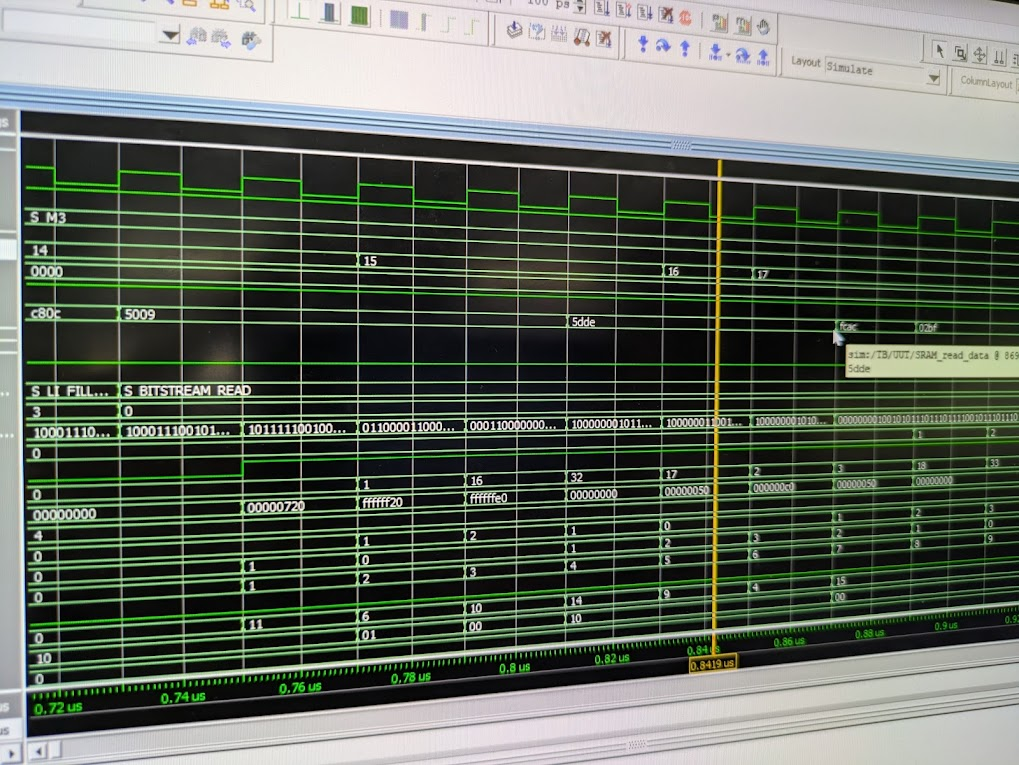
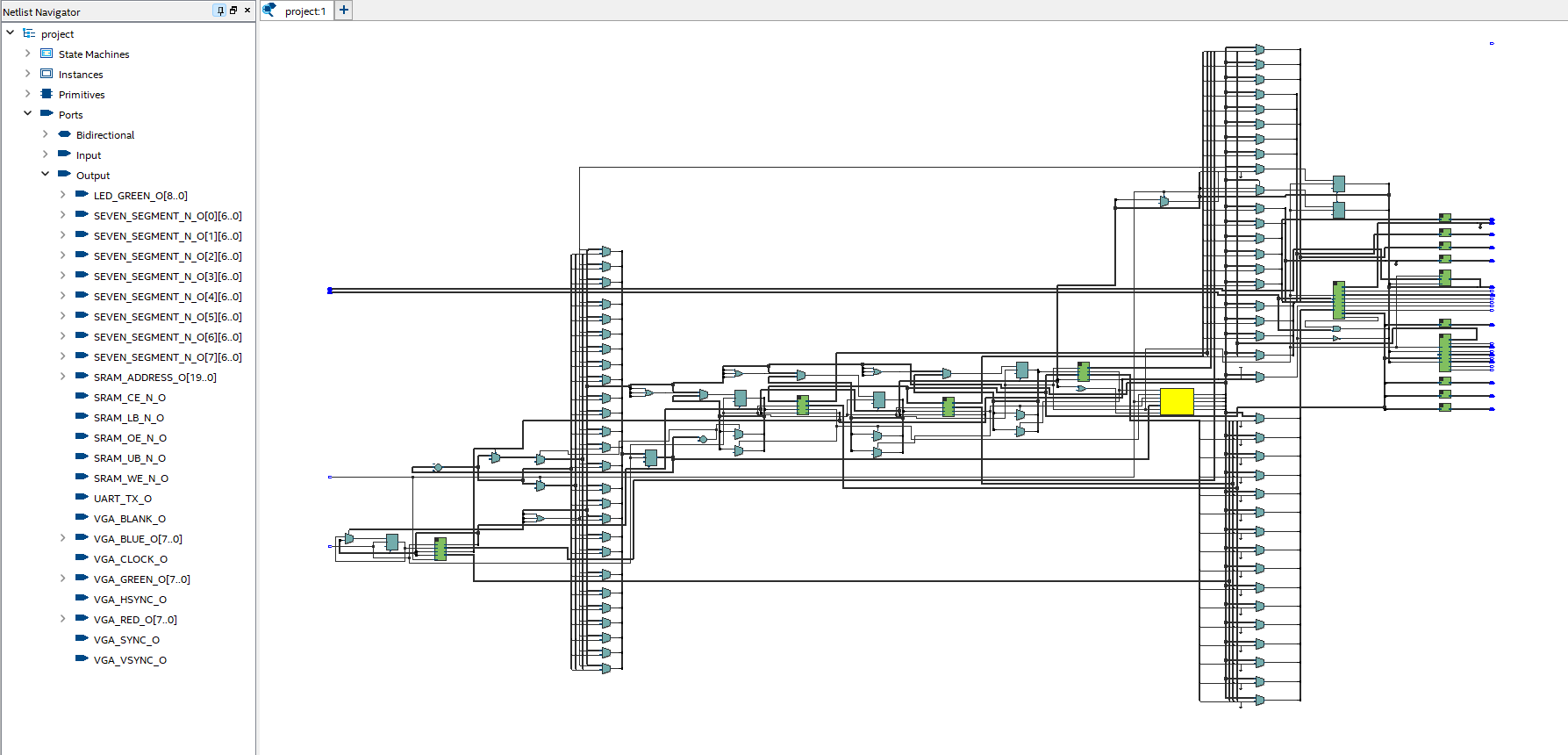
- Manan Dua: Took the lead on the second pass of the IDCT (Compute S) and adapting the arithmetic logic for the Chroma planes during Milestone 2. For Milestone 3, I designed the "Zig-Zag" address counters and the Quantization logic required to reconstruct frequency coefficients from the bitstream.
- Mohammad Mustafa: Optimized register usage in Milestone 1 to ensure we met resource constraints. In Milestone 2, he led the implementation of the first IDCT pass (Compute T). For Milestone 3, he focused on the "Burst Write" logic for the SRAM interface to ensure the decoded data was written back to memory efficiently.